library(rethinking)
data(Wines2012)
data <- Wines2012Statistical Rethinking 2026, A08
R
Bayes
causal inference
MCMC
My solution to exercise A08 from Richard McElreath’s Statistical Rethinking course.
Link to full course on GitHub
Link to online lecture
First, we load the package and data.
Let’s have a look:
'data.frame': 180 obs. of 6 variables:
$ judge : Factor w/ 9 levels "Daniele Meulder",..: 4 4 4 4 4 4 4 4 4 4 ...
$ flight : Factor w/ 2 levels "red","white": 2 2 2 2 2 2 2 2 2 2 ...
$ wine : Factor w/ 20 levels "A1","A2","B1",..: 1 3 5 7 9 11 13 15 17 19 ...
$ score : num 10 13 14 15 8 13 15 11 9 12 ...
$ wine.amer : int 1 1 0 0 1 1 1 0 1 0 ...
$ judge.amer: int 0 0 0 0 0 0 0 0 0 0 ...The data is from a wine-tasting event, where 20 wines (10 from France, 10 from New Jersey) have been tasted by 9 French and American judges.
Now, we want to find out whether there are any differences in harshness or discrimination between French and American judges. Let’s use a DAG to think about this.
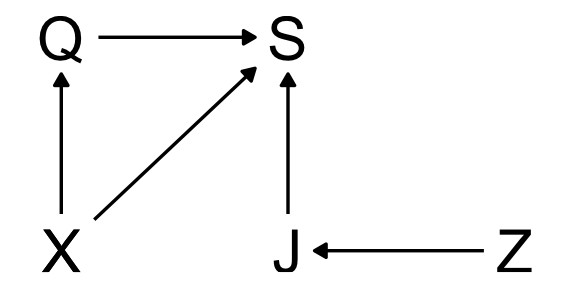
Q = Wine quality
S = Score
X = Wine origin
J = Judge preferences
Z = Judge origin
Statistical Model
The score \(S\) assigned to a wine is modeled as normally distributed around a mean \(\mu\):
\[ \text{S} \sim \mathcal{N}(\mu, \sigma) \] \[ \mu = (\text{Q}_W + \text{O}_X - \text{H}_Z) * \text{D}_Z \]
Inside the brackets, three additive components determine the underlying score before judge effects are applied: \(\text{Q}_W\) is the intrinsic quality of wine \(\text{W}\); \(\text{O}_X\) is a bonus or penalty depending on whether the wine’s origin \(\text{X}\) matches the judge’s prior expectations; and \(\text{H}_Z\) is the harshness of judge \(\text{Z}\), which shifts scores downward. This sum is then multiplied by \(\text{D}_Z\), the discrimination of judge \(\text{Z}\).
Priors
I don’t know what to expect from the model yet, so I’ll first set some default priors but I know that discrimination (\(\text{D}\)) and \(\sigma\) must be positive.
\[ \text{Q} \sim \mathcal{N}(0, 1) \] \[ \text{O} \sim \mathcal{N}(0,1) \] \[ \text{H} \sim \mathcal{N}(0,1) \] \[ \text{D} \sim \text{exponential}(1) \] \[ \sigma \sim \text{exponential}(1) \]
Prepare data
Now we need to prepare the data. This includes standardizing the outcome variable, \(\text{S}\).
data <- list(
S = standardize(data$score),
W = data$wine,
X = ifelse(data$wine.amer == 1, 1, 2), # 1 = american wine, 2 = french wine
Z = ifelse(data$judge.amer == 1, 1, 2) # 1 = american judge, 2 = french judge
)Fit model
Let’s try and fit the model:
m.wines <- ulam(
alist(
S ~ dnorm(mu, sigma),
mu <- (Q[W] + O[X] - H[Z]) * D[Z],
Q[W] ~ dnorm(0, 1),
O[X] ~ dnorm(0, 1),
H[Z] ~ dnorm(0, 1),
D[Z] ~ dexp(1),
sigma ~ dexp(1)
),
data = data, chains = 4
)show(m.wines)Hamiltonian Monte Carlo approximation
2000 samples from 4 chains
Sampling durations (seconds):
chain_id warmup sampling total
1 1 0.15 0.11 0.26
2 2 0.18 0.10 0.28
3 3 0.12 0.06 0.17
4 4 0.17 0.06 0.23
Formula:
S ~ dnorm(mu, sigma)
mu <- (Q[W] + O[X] - H[Z]) * D[Z]
Q[W] ~ dnorm(0, 1)
O[X] ~ dnorm(0, 1)
H[Z] ~ dnorm(0, 1)
D[Z] ~ dexp(1)
sigma ~ dexp(1)precis(m.wines, depth = 2) mean sd 5.5% 94.5% rhat ess_bulk
Q[1] 0.13898657 0.95091591 -1.37371099 1.6226307 1.0011342 2460.2376
Q[2] 0.02404382 0.90457143 -1.39590944 1.4796395 1.0038372 2658.6588
Q[3] 0.30245330 0.94186181 -1.17924418 1.7563533 1.0011300 2042.2848
Q[4] 0.49164692 0.91733864 -1.04148070 1.8912420 1.0007380 2576.1201
Q[5] -0.23277490 0.91303810 -1.71547279 1.2194583 1.0056789 2435.1156
Q[6] -0.36041352 0.95513998 -1.82955651 1.2034704 1.0001668 2334.1285
Q[7] 0.22087531 0.92446803 -1.21146869 1.7151020 1.0021462 3023.2336
Q[8] 0.33872271 0.96211636 -1.24787694 1.8362625 1.0055485 2628.7546
Q[9] 0.10720325 0.89798351 -1.31296884 1.5268290 1.0030748 3241.9919
Q[10] 0.18718525 0.91168806 -1.27893737 1.6404832 1.0003151 3055.6738
Q[11] 0.06362231 0.91240021 -1.39078481 1.5267090 0.9993600 3328.7920
Q[12] -0.01551917 0.91144530 -1.45569178 1.4409729 1.0020779 2578.0100
Q[13] -0.05038415 0.93498467 -1.56141618 1.4119429 1.0031313 2443.8173
Q[14] -0.05890552 0.90232975 -1.45999880 1.3937685 1.0026310 2805.0109
Q[15] -0.27739038 0.97189889 -1.80871537 1.3659562 1.0029518 2700.8100
Q[16] -0.16520380 0.96320676 -1.71778350 1.3688729 0.9997498 2353.1034
Q[17] -0.09041826 0.89706393 -1.57795747 1.3499541 1.0028688 2672.0010
Q[18] -0.79653050 0.96416025 -2.36354981 0.7831015 1.0028187 1631.3314
Q[19] -0.25647048 0.93819956 -1.80207074 1.2568909 0.9997797 2635.0625
Q[20] 0.31495959 0.96086553 -1.21263423 1.8125656 0.9992842 1832.3115
O[1] -0.32723373 0.75514940 -1.49053377 0.9090946 1.0005727 1831.8929
O[2] 0.31054550 0.77726830 -0.94108328 1.5649165 1.0008442 2134.5977
H[1] -0.46791142 0.78205098 -1.66888588 0.8189812 1.0040092 1857.6294
H[2] 0.42980736 0.82610208 -0.89199113 1.7157534 1.0007080 1813.3030
D[1] 0.11861852 0.08786658 0.01298841 0.2797960 1.0057014 865.9650
D[2] 0.13804928 0.10893690 0.01203305 0.3453178 1.0039177 770.5017
sigma 0.99198016 0.05288462 0.91096037 1.0816254 1.0054380 1844.8327trankplot(m.wines)
Waiting to draw page 2 of 2
Causal contrast
Total causal contrast in mean: wine discrimination
Code
post <- extract.samples(m.wines)
mu_contrast <- post$D[, 2] - post$D[, 1] # french - american discrimination
dens(
mu_contrast,
lwd = 2,
xlab = "posterior mean discrimination contrast"
)
Total causal contrast in predicted score: wine discrimination
Code
# sample from posterior
D_A <- rnorm(1000, post$D[, 1], post$sigma)
D_F <- rnorm(1000, post$D[, 2], post$sigma)
# calculate contrast
S_contrast <- D_F - D_A
dens(
S_contrast,
lwd = 2,
xlab = "posterior contrast in discrimination (French - American)"
)
Here we can see that 51.5% of the times we randomly sample a new judge, the French judge is more discriminating than the American judge. And 48.5% of the time, the American judge is more discriminating than the French judge. So it seems like there is no difference between American and French wine judges in terms of wine discrimination.
Let’s now look at harshness.
Total causal contrast in mean: harshness
Code
mu_contrast_H <- post$H[, 2] - post$H[, 1] # french - american discrimination
dens(
mu_contrast_H,
lwd = 2,
xlab = "posterior mean harshness contrast"
)
Total causal contrast in predicted score: harshness
Code
# sample from posterior
H_A <- rnorm(1000, post$H[, 1], post$sigma)
H_F <- rnorm(1000, post$H[, 2], post$sigma)
# calculate contrast
S_contrast_H <- H_F - H_A
dens(
S_contrast_H,
lwd = 2,
xlab = "posterior contrast in harshness (French - American)"
)
Here we can see that 70.6% of the times we randomly sample a new judge, the French judge is more harsh in their judgement than the American judge. And 29.4% of the time, the American judge is more harsh in their judgement than the French judge.
Lineplot
Now I want to try to recreate the lineplot that McElreath showed in his slides.
First, we need to create a sequence of wine quality (Q).
library(tidyverse)
# Simulation settings
n_lines <- 40
Q_seq <- seq(-2, 2, len = 60)
# 1 = American, 2 = French
Z_american <- 1
Z_french <- 2Now, we need a function that gets the right values out of the posteriors. We first sample indices from the posterior, so that we “decide” a priori what row from the posterior we’ll use. In the for loop, we then fill the empty list we initiated with values from the full posterior in order to get the trajectories for a given Z.
make_lines <- function(Z_val, n_lines, Q_seq, post) {
idx <- sample(nrow(post$sigma), n_lines, replace = FALSE)
results <- vector("list", length(idx))
for (i in seq_along(idx)) {
s <- idx[i] # Full posterior draw: O, H & D come from the same sample row
X_draw <- sample(1:2, 1) # random wine origin
O <- post$O[s, X_draw]
H <- post$H[s, Z_val]
D <- post$D[s, Z_val]
results[[i]] <- data.frame(
Q = Q_seq,
mu = (Q_seq + O - H) * D,
line = i
)
}
# Combine all the individual data frames into one
do.call(rbind, results)
}Now, we just call the function twice (for French and American judges) and then combine both data frames the data by row-binding it.
df_plot <- bind_rows(
make_lines(Z_american, n_lines, Q_seq, post) |>
mutate(judge_origin = "American"),
make_lines(Z_french, n_lines, Q_seq, post) |>
mutate(judge_origin = "French")
) |>
mutate(judge_origin = factor(judge_origin, levels = c("American", "French")))And now we’re ready to plot!
ggplot(df_plot, aes(x = Q, y = mu, group = line)) +
geom_vline(xintercept = 0, col = "lightcoral") +
geom_hline(yintercept = 0, col = "lightcoral") +
geom_line(alpha = 0.35, linewidth = 0.5, colour = "#2c7bb6") +
facet_wrap(~judge_origin, ncol = 2) +
labs(
x = "Wine quality (Q)",
y = "Predicted score (μ)",
title = "Predicted scores by judge origin",
subtitle = paste0(n_lines, " posterior draws per panel")
) +
theme_classic()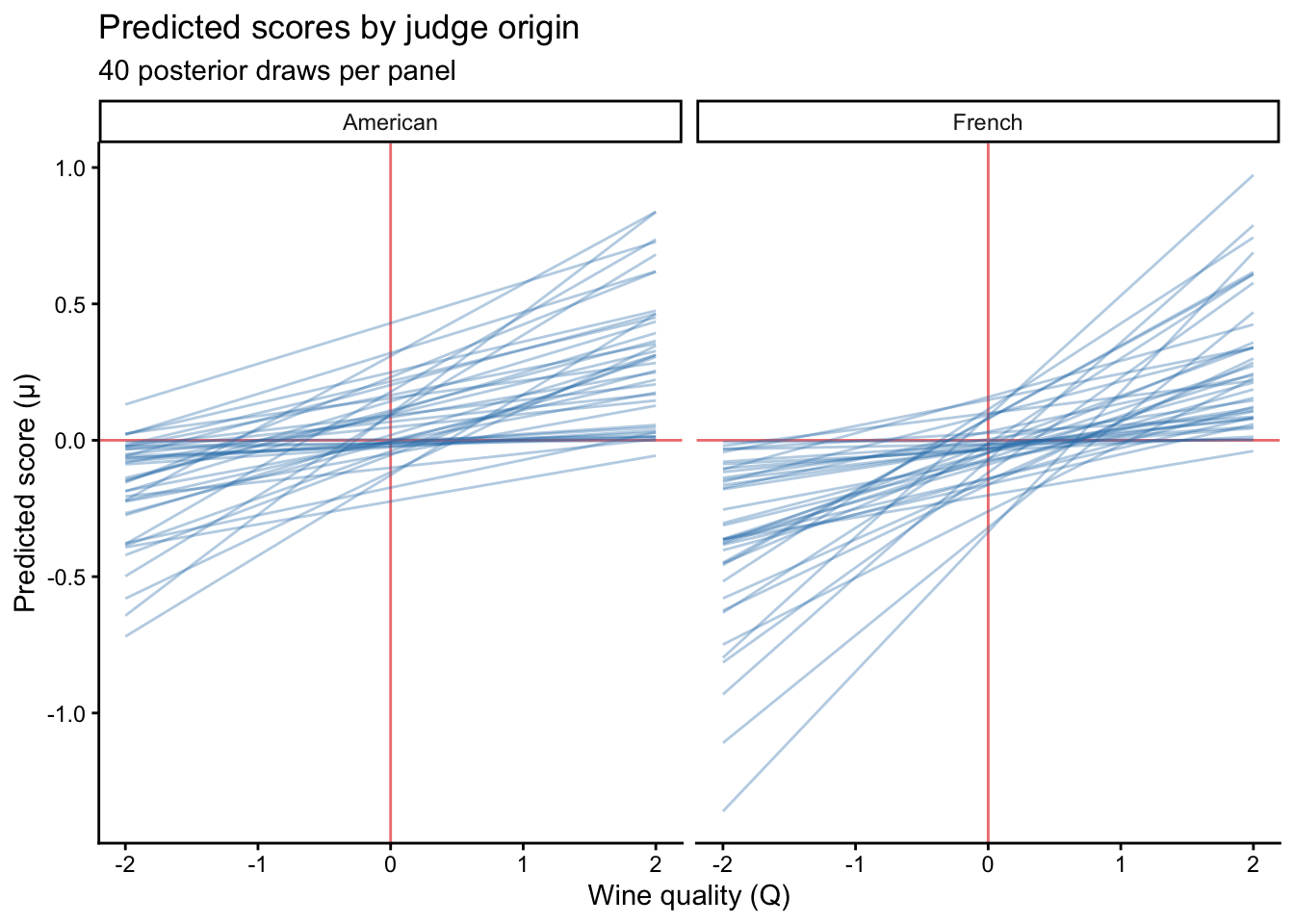
So: do the French and American judges actually differ in either their harshness or discrimination? Yes, they do differ in harshness. French judges tend to give lower scores in general compared to American judges. But their discrimination between wines does not differ.